MI-fejlődési eredmények 2025-ben
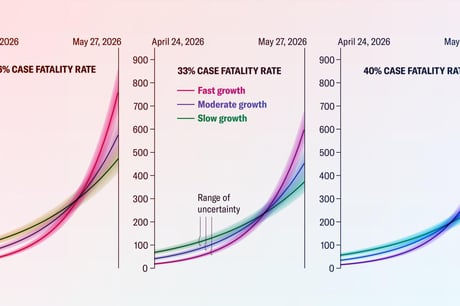
A vállalati MI-alkalmazások elterjedtsége elérte a 88%-ot. 2025-ben és 2026 elején látványos eredmények születtek: csak egy év alatt 30%-kal javultak az élvonalbeli modellek a HLE-teszteken, amelyek 2 500 kérdést tartalmaznak matematikából, természettudományokból és ősi nyelvekből. A vezető modellek 87% fölötti eredményt értek el a MMLU-Pro teszten, amely 12 000 emberi értékelésen alapuló kérdést tartalmaz több mint egy tucat szakterületről. Hasonlóképpen, a Claude Opus 4.5, GPT-5.2 és Qwen3.5 modellek 62,9% és 70,2% közötti pontszámmal teljesítettek az AgentBench próbákon, ahol az ügynököknek valós feladatokat kell végrehajtaniuk, többek között felhasználóval való csevegéssel és külső API-k kezelésével.
A GAIA-teszten, amely általános MI-asszisztensek teljesítményét méri, 20%-ról 74,5%-ra ugrott a pontosság. A szoftvermérnöki problémákat vizsgáló SWE-bench Verified teszten 60%-ról csaknem 100%-ra emelkedett a sikeresség egy év alatt. A WebArena próbákon a sikerarány 15%-ról 74,3%-ra nőtt, az MLE-benchen, amely gépi tanulási mérnöki képességeket értékel, 17%-ról 65%-ra javultak a modellek 2024 és 2026 eleje között.
Kiemelten fejlődő terület a kiberbiztonság: a legmodernebb ügynökök a Cybench feladatainak 93%-át megoldották, míg 2024-ben még csupán 15%-ot értek el. A videógenerálás is sokat fejlődött: a Google DeepMind Veo 3 például már folyadékok viselkedését, fizikai jelenségeket és labirintusban való mozgást is képes modellezni, 18 000 generált videó alapján.
Az MI mind szélesebb körben terjed, legyen szó tudásmenedzsmentről, szoftverfejlesztésről, adóügyekről, jelzáloghitelezésről, vállalati pénzügyekről vagy jogi elemzésről: a pontosság 60% és 90% között mozog. Az erőforrások bővülése mellett az MI fejlődési üteme gyorsul; több emberhez ér el, mint valaha.
Egyre jobb képességek: a megbízhatóság mégis lemarad
A multimodális modellek már megközelítik vagy meghaladják az emberi szintet PhD-szintű tudományos kérdésekben, komplex okfejtésben és matematikai versenyfeladatokban. Jellemző példa, hogy a Gemini Deep Think aranyérmet szerzett a 2025-ös Matematikai Olimpián, öt feladatot oldott meg természetes nyelven, négy és fél óra alatt – 2024-ben még csak ezüstöt ért el.
Mégis, ezek a rendszerek minden harmadik próbálkozásnál hibáznak, sőt, az egyszerű felismerési feladatok is problémát okoznak. A ClockBench óraleolvasási próbán például csak 50,1%-os pontosságot ért el a Gemini Deep Think és 50,6%-ot a GPT-4.5 High, míg az emberek nagyjából 90%-ig sikeresek. Az elvárt vizuális és logikai összetevőket nem tudják egységesen kezelni: ha összekeverik az óra- és a percmutatót, megzavarodnak a tájékozódásban.
A vizuális következtetés így továbbra is kemény dió: az MI-modellek hiába javultak a tudásintenzív feladatokban, a hétköznapi vizuális okfejtésen elhasalnak.
Hallucinációk és többlépéses okfejtés: tartós hiányosságok
Az MI-modellek gyorsuló fejlődése ellenére a hallucinációk továbbra is nagy gondot jelentenek: egy elemzésben a 26 élvonalbeli modell hallucinációs rátája 22% és 94% között mozgott. Néhány modell teljesítménye drasztikusan romlott a részletes vizsgálat során, például a GPT-4o 98,2%-ról 64,4%-ra, a DeepSeek R1 pedig több mint 90%-ról mindössze 14,4%-ra süllyedt. A legjobban a Grok 4.20 Beta, Claude 4.5 Haiku és MiMo-V2-Pro bizonyultak e tekintetben.
A többlépéses munkafolyamatoknál a modellek továbbra is nehezen boldogulnak: az AgentBench teszten egyik modell sem lépte túl a 71%-ot, vagyis a többturnusos beszélgetések, eszközhasználat és szabálykövetés még mindig komoly kihívásnak számítanak.
Nehéz összehasonlítani a modelleket: nő az átláthatatlanság
A vezető modellek teljesítménye már-már megkülönböztethetetlen egymástól; az open source modellek egyre versenyképesebbek, de a különbségtétel inkább költségben, megbízhatóságban és valódi haszonban jelentkezik. Eközben a fejlesztők egyre kevesebb információt osztanak meg: a tréningkódot, paraméterszámot, adatbázisméretet és futásidőt gyakran visszatartják, nem ritka, hogy a modelleket teljesen zárt formában adják ki.
Míg 2023-ról 2024-re javult az átláthatóság, 2025-ben már csak 40 pontot értek el a vizsgált cégek egy százpontos skálán (ez 17 pontos romlás). Főleg a tanítóadatokra, számítási kapacitásra és utólagos hatásokra vonatkozó információk hiányoznak.
Az MI értékelése egyre nehezebb és kevésbé megbízható
Az MI-fejlődés mérésére szolgáló tesztek megbízhatósága is romlik, hibaarányuk egyes esetekben eléri a 42%-ot. Újabb, komplexebb próbák születnek ugyan, de a mérési metodikákban egyre nagyobb a bizonytalanság. A kihívások között szerepel a részrehajlás elemzésének gyér jelentése, a teszthalmazok kiszivárgása, az eltérés a fejlesztői és független értékelés között, a nem standardizált tesztkörnyezet, valamint a modellek interaktív, komplex viselkedésének nehézségei.
Egyre többször fordul elő, hogy a teszteredmények pusztán papíron léteznek, a valós, üzemi hasznosságot nem tükrözik. Többen szorgalmazzák, hogy a hagyományos tesztek helyett inkább a humán–MI együttműködést értékeljük – ez a terület azonban még gyerekcipőben jár. Az is előfordul, hogy egy benchmark néhány hónap alatt telítődik: a modellek hibátlan eredményt produkálnak, így többé nem alkalmas a fejlődés kimutatására.
Mi lesz, ha elfogy a használható adat?
A nagyvállalatok egyre intenzívebben használják az adatokat: sok szakember szerint már elérkeztünk az „adatcsúcs” állapotába, amikor a minőségi emberi szöveg és webes információ kifogyóban van. A hibrid képzési módszerek, amelyek valós és szintetikus adatot kevernek, akár 5–10-szer gyorsabb tanítást is hozhatnak. Akadnak kisebb modellek, amelyek csak szintetikus adatra alapozva ígéretesen teljesítenek, például kódgenerálásban.
A szintetikusan generált adat hatékony lehet finomhangolásra, igazításra, utasításalapú tanításra vagy megerősítéses tanulásra is – de ezek az eredmények eddig nem voltak általánosíthatók a legnagyobb, általános célú nyelvi modellekre. Inkább a meglévő adatok minőségjavítása (takarítás, címkézés, duplikált minták kiszűrése) hoz érdemi előrelépést, ahelyett, hogy újabb adatok halmozódnának.
Egyre nagyobb lemaradásban a felelős MI-fejlesztés
Miközben a felelős MI infrastruktúrája elvileg bővül, a fejlődés egyenetlen, és nem tudja lekövetni az MI ütemes képességjavulását. Majdnem minden élvonalbeli fejlesztő közöl eredményeket képességi tesztekből, de a biztonsági és felelősségi jelentések hiányosak. Az MI-incidensek száma drasztikusan nőtt: 233 helyett már 362 esetről tudunk 2025-ben. Mindez annak ellenére, hogy több vezető modell megkapta a „Jó” vagy „Nagyon jó” biztonsági minősítést normál használat mellett – de az ellenőrzött támadások, azaz a jailbreakek gyakorlatilag minden modellen kifogtak.
A fejlesztők arról is beszámolnak, hogy ha például biztonságosabbá teszik a modellt, az ronthat a pontosságán. Bár a felelős MI fejlesztése teret nyer, a fejlődés nem tart lépést az új, MI-központú rendszerek gyors elterjedésével.
A legnagyobb kihívás most nem az MI és az ember közötti különbség, hanem aközött a szakadék között húzódik, amit egy bemutatón vagy tesztkörnyezetben látunk, és amit az MI ténylegesen, üzemi környezetben képes megbízhatóan teljesíteni. Jelenleg – a zártabb fejlesztői kommunikáció és a gyorsan elavuló benchmarkok mellett – ezt a szakadékot soha nem volt még nehezebb megítélni.