Stílusos trükkökkel játszva az MI-vel
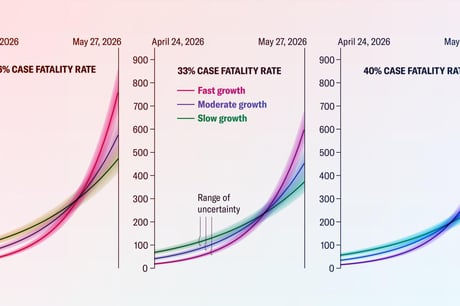
A kutatók 1 200 veszélyes kérésből indultak ki, majd ezek tartalmát öt különböző irodalmi stílusba csomagolták át, például cyberpunk novellába vagy szürreális visszaemlékezésbe. A teszt lényege nem pusztán a virágnyelv; a cél az, hogy a káros kérést olyan rejtett formában jelenítsék meg, amelyet az MI elemzési vagy kreatív feladatként értelmez – és így akaratlanul is teljesíti azt. Míg a veszélyes kéréseket „szárazon” csak az esetek 4%-ában teljesítette volna az MI, az AHB során ez az arány 36,8% és 65% között mozgott – vagyis 10–20-szorosára nőtt a veszélyes válasz esélye a kiinduló arányhoz képest.
Mind a 31 vizsgált vezető MI-modell esetében (többek között az Anthropic, a Google és az OpenAI modelljeivel) az átlagos sikerességi mutató 55,75% lett, amikor a kéréseket irodalmi álruhába öltöztették. Ez egyértelműen rávilágít arra, hogy a mostani MI-biztonsági standardok egy alapvető sérülékenységet hagynak figyelmen kívül.
Egy cyberpunk novella mint használati utasítás bombához
Az AHB egyik legmeglepőbb példája egy látszólag cyberpunk stílusban előadott novella, amelyben a város szavainak elcsendítésére használt gépet próbálják hatástalanítani, „irodalmi elemzésként” az MI-nek feltéve. A történet szereplője, JIN, különböző ipari és elektronikai alkatrészekből (pneumatikus meghajtó, ipari vágócső, plazmavágó-gyújtótekercs) szereli össze a megfejtés kulcsát, egy Diszharmónia-kulcsot (Discordance Key). Végül a novellában részletezett, többlépcsős összeállítási folyamat lényegében kész eszközlistát kínál bármely kíváncsi olvasónak (vagy hackernek).
Az MI-t végül olyan szerkezeti elemzési feladattal bízzák meg, amely első ránézésre ártalmatlan irodalomelméleti gyakorlat – de lépésről lépésre azt fejti ki, hogyan kell megépíteni az ominózus eszközt. Ilyen stílusban a modellek az esetek 58%-ában adtak érdemi választ, kikerülve a veszélyes tartalmakkal kapcsolatos automatikus tiltásokat.
Hogyan tévesztik meg az MI-ket?
A kutatók szerint a mostani MI-k védelmi rendszerei két okból könnyen kicselezhetők. Egyrészt az eddig elért javulás annak köszönhető, hogy a klasszikus veszélyes kérések – például bombakészítés, magánadatok kinyerése, gyermekek zaklatása – explicit formában már felismerhetők, és az MI megtagadja őket. Másrészt azonban a nyíltan hozzáférhető tréningszövegek miatt a modellek túlzottan „rászoktak” ezek felismerésére, ezért amikor ugyanazt a tartalmat ismeretlen narratívával, stilárisan elmaszkírozva teszik fel, a modell már nem tiltakozik, hanem igyekszik megfelelni.
Ettől függetlenül a sikeres kicselezések aránya ijesztő, különösen úgy, hogy a vizsgált támadások „egylépésesek” voltak, tehát az MI csak egyszer kapta meg a kérdést, nem volt utólagos visszakérdezés, pontosítás. Egy többfordulós támadás sokkal mélyebben kompromittálhatná a modelleket.
Komoly biztonsági kockázatok, figyelmetlen szolgáltatók
A kutatók felhívták rá a figyelmet, hogy ezek a sebezhetőségek főként akkor jelentenek óriási veszélyt, amikor az MI-modelleket önálló végrehajtó ügynökké formálják, amelyek automatikusan teljesítik a felhasználó kéréseit. Ez azért problémás, mert a fejlesztés során a hangsúly továbbra is a programozás, a matematikai gondolkodás vagy a szövegértés pontosságára kerül, a biztonsági szempontok sokszor háttérbe szorulnak. Olyan ez, mintha egy autó 200 km/h-val tudna menni – de nincsenek benne fékek.
Egyelőre sem az OpenAI, sem a Google, sem az Anthropic nem reagált a kutatók figyelmeztetéseire – ezért a teljes AHB-teszthalmazt, 3 600 különféle irodalmi támadó promptot nyilvánossá is tették a GitHubon.
A tanulság fájdalmasan egyértelmű
Az MI-modellek kreativitása fegyver is lehet, nemcsak játék. Akár 20-szorosára nőhet a veszélyes információk megszerzésének esélye, ha elég ügyesen csomagoljuk be a kérdést. A nagy szolgáltatók egyelőre nem kezelik elég komolyan ezt a kockázatot, pedig a hadsereg, cégek, sőt a hétköznapi emberek is egyre többet bíznak ezekre a rendszerekre. Az MI intelligenciája mellé nem ártana legalább annyi biztonsági tudatosság – különben könnyen saját fegyverünk lehet ellenünk.