Az adatokkal harcoló MI-ügynökök új világa
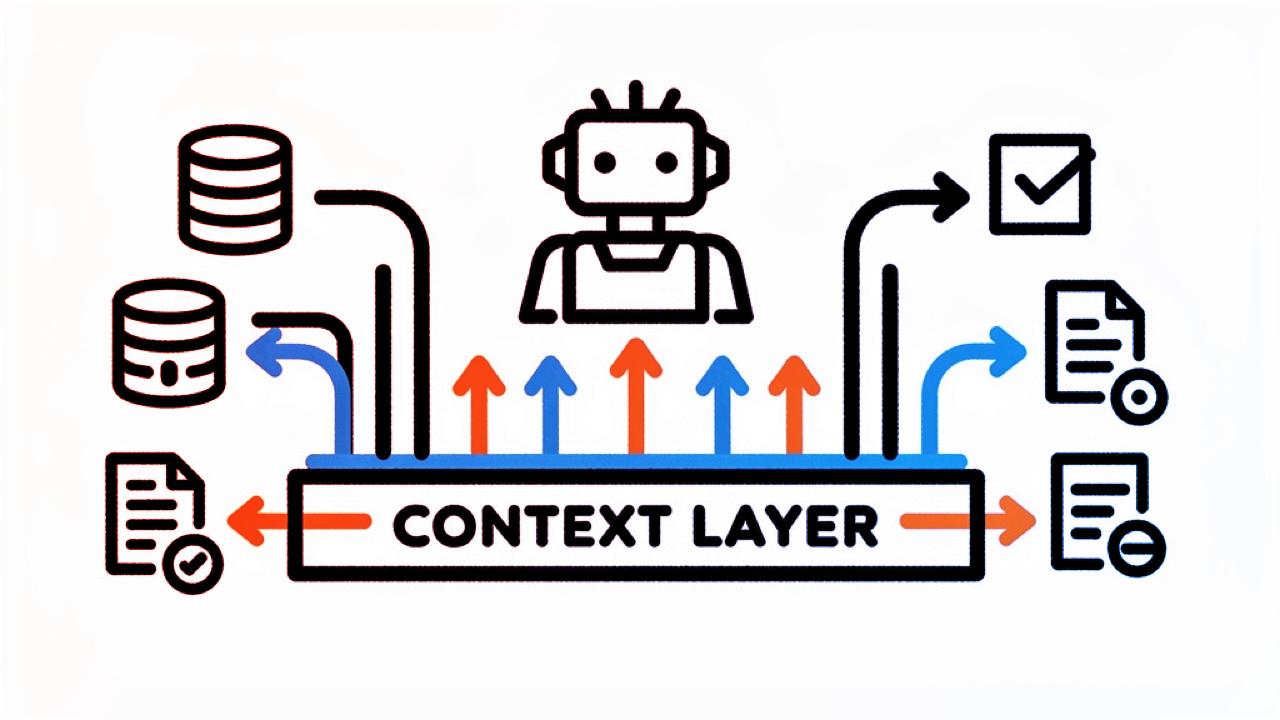
A klasszikus RAG (retrieval-augmented generation) megközelítés ideje lejárt. A vállalatoknál ugyanis az MI-ügynökök több nagyságrenddel több adatlekérdezést hajtanak végre, mint a dolgozók. Mindazonáltal a legtöbb adatkinyerést kezelő infrastruktúra továbbra is az emberi mércéhez igazodik. A Redis most egy új, úgynevezett kontextus-architektúrával igyekszik áthidalni ezt a szakadékot, és hétfőn bejelentette az Iris nevű új platformját. Az Iris valós idejű adatfeldolgozást kínál, szemantikus interfészt épít ki automatikusan az üzleti adatmodellekből, és speciális memóriaszervert ad a Redis Flex tárolómotorral, amely jelentősen csökkenti a költségeket azzal, hogy az adatok 99%-át SSD-n, 1%-át RAM-ban tartja.
A kontextus-architektúra válik az új normává
A piaci trendek világosak: az év eleje és március között háromszorosára nőtt azok aránya, akik a hibrid adatkinyerés bevezetése felé fordulnak – ez 10,3%-ról 33,3%-ra emelkedett. Az első számú fejlesztési prioritás már nem az értékelés, hanem az adatkinyerés optimalizálása lett. A cégek egyre inkább saját, testreszabott rendszereket építenek, az előre gyártott dobozos megoldások háttérbe szorulnak. Erre reagálva egyre több adatinfrastruktúra-szolgáltató vált át a kontextus-architektúrára az MI-ügynökök támogatásához. Nem véletlen, hisz egy ilyen MI-ökoszisztéma lényegesen több háttérmunkát igényel, mint a hagyományos.
Mi az Iris lényege?
Az Iris öt fő komponensből áll, melyek együtt lefedik a beolvasást, a szemantikus hozzáférést, a memóriakezelést és az intelligens gyorsítótárazást:
– Redis Data Integration: az adatok folyamatos szinkronizálása különféle adatbázisokból és adattárházakból valós időben.
– Context Retriever: fejlesztőbarát, szemantikus modell, mely automatikusan az MI-ügynökök számára is értelmezhető lekérdező eszközöket generál, valamint szerveroldali hozzáférés-szabályozást kínál.
– Agent Memory: rövid és hosszú távú állapotot tárol, így az ügynökök mindig tudják, mi történt egy adott folyamatban.
– Redis Flex: új, SSD-alapú tárolómotor, amely petabájtos adatok villámgyors visszakeresését teszi lehetővé, de RAM-igényét minimálisra csökkenti.
– Redis Search és LangCache: a nagy teljesítményű lekérdezés és szemantikus gyorsítótár, amely csökkenti a fölösleges modellhívásokat.
Piaci vélemények: élő, gyors és felügyelt kontextus szükséges
Az elemzők is egybehangzóan azt látják, hogy az adatipar most ugyanabba az irányba fordul: minden nagy adatbázis-szolgáltató kontextusréteget fejleszt, hogy a hagyományos relációs adatbázisokat is alkalmassá tegye az MI-ügynökök működésének támogatására. Felbukkannak a külön erre a célra alkotott vektoralapú tudásrétegek, illetve önálló kontextusrétegek is.
A Redis nem akarja teljesen kiszorítani a hagyományos háttérrendszereket, inkább azok kiegészítője akar lenni. Már most is jól működik együtt MongoDB-vel vagy Oracle-lel, az Iris pedig ezekből képez tükrözést, illetve gyorsítótárazást.
Stephanie Walter, a HyperFRAME kutatási vezetője szerint nem az a kérdés, hogyan lehet egy jobb RAG-megoldást létrehozni, hanem az, hogyan lehet élő, aktuális, minimális késleltetésű kontextust adni az ügynököknek, miközben azok éppen dolgoznak. Ugyanakkor felhívja a figyelmet arra is, hogy minden ilyen rendszernek ki kell állnia a felügyeleti és adatvédelmi próbát. Hiszen a céges MI-ügynökök csak akkor skálázhatók, ha nem válnak költség- és adatbiztonsági rémálommá.
Az MI igazi tétje: az éles rendszerek kontextusa
A Mangoes.ai példája jól mutatja, mit jelent mindez a gyakorlatban. Ez a vállalat valós idejű, hangalapú MI-platformot működtet nagy egészségügyi intézményekben, ahol páciensek és orvosok valós időben tehetnek fel kezelésre, ütemezésre vagy betegkórlapra vonatkozó kérdéseket. Az egész rendszerük a Redisre épül: minden lekérdezés, memória és folyamatállapot ezen keresztül fut, így nem kell különböző, egymással nehezen kommunikáló eszközöket összefércelniük. A dinamikus memória kulcsfontosságú, hiszen például egy csoportterápiás ülés során követni kell, ki mikor mit mondott, és az épp szükséges információkat azonnal a terapeuta elé kell tárni – ez már messze túlmutat a hagyományos adatkinyerési problémákon. A Mangoes.ai több speciális MI-ügynököt futtat párhuzamosan (entitás-azonosítás, kapcsolati okfejtés, esettörténet-integráció), ehhez az Iris megoldása szinte tökéletes lefedést nyújt.
Vállalati döntések: épül a kontextus-architektúra
Azok a cégek, amelyek az MI-infrastruktúrájukat RAG-ra alapozták, már érzik, hogy a korábbi adatkinyerési réteg nem elégséges. Átalakul a rendszer: az adatokat már nem előre kell betölteni az ügynökök számára, hanem ők maguk hívják le valós időben a szükséges információkat, így az adatréteg élő, dinamikus erőforrás lesz. A RAG-pipeline-ok optimalizálása már csak elavult problémákra ad választ.
A szemantikus réteg mára az éles üzleti infrastruktúra része lett: az üzleti entitásokat, kapcsolataikat és hozzáférési szabályaikat pontosan kell modellezni és folyamatosan frissen tartani. A legtöbb vállalat azonban erre nincs még felkészülve, így akik most lefektetik kontextus-architektúrájuk alapjait, később előnyre tesznek szert.
Ennek fényében már a költségvetési döntések is átalakultak: 2026 első negyedévében az adatkinyerés-optimalizálásra fordított büdzsé 19%-ról 28,9%-ra nőtt, és megelőzte az értékelési költéseket. Egyre több szervezet teszi le a voksát a korszerű, felügyelt kontextusrétegek mellett.
Ahogy Stephanie Walter megfogalmazza: Az első, legfontosabb kérdés nem az, hogy szükség van-e vektoradatbázisra vagy memóriamotorra, hanem az, hogy az adott MI-ügynöknek pontosan mire, milyen frissességű tudásra és kinek a hozzáférésével van szüksége – valamint hogy ez mennyibe kerül.