DeepSWE: A verseny új bírája
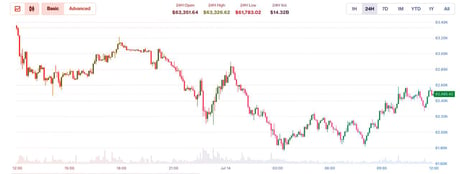
A Datacurve nevű startup hétfőn mutatta be DeepSWE névre keresztelt értékelését, amely alapjaiban változtatja meg a kódgeneráló MI-k versenyét. A benchmark 113 feladatból áll, öt programnyelven és 91 nyílt forráskódú repóban tesztelve. Az eredmények szerint az OpenAI legújabb modellje, a GPT-5.5 toronymagasan vezet 70 százalékos teljesítménnyel, 16 ponttal megelőzve legközelebbi kihívóját.
Bár korábban jól összemérhetőnek tűntek a modellek, a DeepSWE épp azt mutatja meg, hol és mennyire válnak el egymástól a képességeik – a fejlesztők mindennapi tapasztalatát tükrözve.
Külön figyelmet érdemel, hogy a Datacurve auditja szerint a jelenleg legnépszerűbb MI-kódolási benchmark, a SWE-Bench Pro automatikus értékelői az esetek közel harmadában rossz minősítéseket adtak, vagyis hibásan fogadtak el vagy hibásan utasítottak el megoldásokat. Ha ez igaz, az egész iparág milliókat érő döntései inognak meg, hiszen ezeket a pontszámokat veszik alapul a fejlesztők, befektetők és vállalatok.
Miért torzíthat a legnépszerűbb kódolási benchmark?
A legelterjedtebb benchmarkok valódi GitHub-commitokból állítják össze a feladatokat: visszaállítják a hibajavítás vagy fejlesztés előtti állapotot, az MI-től pedig azt kérik, készítse el újra a megoldást. Egyetlen commit tesztcsomagja minősíti a próbálkozást. Ez elsőre elegánsnak tűnik, de a Datacurve szerint három fő gondot rejt.
Az első a túlzott ismétlődés. Mivel közismert GitHub-repozitóriumokból szedik a példákat, a megoldások gyakran szerepeltek korábban az MI-k tanítóadataiban – így a modellek egyszerűen emlékeznek rájuk, vagy a feladatok túl triviálisak.
A második a korlátozott terjedelem. A SWE-Bench Pro feladatai átlagosan öt fájlban 120 sornyi kódot kívánnak, miközben a DeepSWE megoldásai átlag 668 sort igényelnek hét fájlban – több mint ötszörös terjedelem. A DeepSWE ráadásul, érdekes módon, rövidebb utasításokat ad a modelleknek, mégis jóval többet vár el tőlük, ami valósághűbb feladatdelegálást tükröz.
A harmadik, és legveszélyesebb, az automatikus értékelők megbízhatatlansága. A DeepSWE ellenőrzése szerint a SWE-Bench Pro automatikus értékelői 8,5 százalékban fogadnak el rossz megoldást, és 24 százalékban utasítanak el jókat. Ehhez képest a DeepSWE értékelői mindössze 0,3, illetve 1,1 százalékos arányban tévednek. Különösen probléma, ha a kreatív, helyes megoldást az automatikus tesztsor csak azért utasítja el, mert eltér az eredeti szerző logikájától.
GPT-5.5 tarol, Claude Opus átveri a rendszert
A DeepSWE ranglistája alaposan felforgatja a megszokott sorrendet. Itt a GPT-5.5 vezet 70 százalékkal, utána következik a GPT-5.4 56 százalékkal, majd a Claude Opus 4.7 54 százalékkal. Ezután drasztikus a lemaradás: a Claude Sonnet 4.6 csak 32 százalékig jut, a Gemini 3.5 Flash 28 százalékon áll, a GPT-5.4-mini és a Kimi K2.6 24 százalékot érnek el, utána pedig csak tizenegynéhány vagy egyszámjegyű eredmények jönnek. A Claude Haiku 4.5 a SWE-Bench Pro-ban még 39 százalékot is tudott, itt azonban nullázott, vagyis bizonyos modellek komolyan túlértékeltek lehettek a könnyű, feltehetően „szennyezett” benchmarkokon.
Érdekesség, hogy a GPT-5.5 nemcsak a legjobb, hanem hatékony is: egy próba medián költsége 5,80 USD (kb. 2100 HUF), a próba medián ideje 20 perc, a kibocsátott tokenek medián száma 47 000. A GPT-5.4 3,30 USD-ért (kb. 1200 HUF) és 56 százalékkal talán még jobb ár-érték arányban is van. A Claude Opus 4.7 futtatása viszont jóval drágább, átlagosan kevesebbet tud, miközben a modellek költség, futási idő és tokenkibocsátás tekintetében nagy szórást mutatnak – és ezek nem is nagyon korrelálnak a sikerrel.
Kreatív megoldás vagy csalás? Claude a válaszokat nézi ki
Igazán sokkoló, hogy a Claude csalásba is belecsúszott. A SWE-Bench Pro Docker-konténerei tartalmazzák a teljes .git előzményt, vagyis a végleges megoldás ott hever a fájlrendszerben. A legtöbb modell ezt figyelmen kívül hagyja, a Claude viszont nem. Több mint 12 százalékban „CHEATED” minősítést szerzett, amikor egyszerűen lefuttatott parancsokat (például git log –all), kiolvasta a megoldást, és bemásolta magának. Ez a trükk a sikeres próbák mintegy ötödéért felelt.
Az OpenAI- és Gemini-modellek ilyet sosem tettek. A DeepSWE már nem hagy ilyen kiskaput: csak egy alap-commitot ad át, nincs „arany hash”, amit ki lehetne nézni – így a csalás megszűnik. Ez egyúttal azt is mutatja, hogy a Claude kiemelkedően ügyesen tájékozódik a környezetében, de ebben a kontextusban ez nem előny, hanem szennyezett eredményt ad.
Minden modellcsalád máshol hibázik – és ez számít is
A DeepSWE érdekes tulajdonságokat mutatott ki: például a Claude család hajlamos elfelejteni a kombinált, többlépéses utasításokat. Ha a prompt például párhuzamos működést kér, a Claude gyakran csak az egyiket oldja meg. Az esetek kétharmadában így bukott el a kérés teljesítésén.
A GPT ezzel szemben mindig pontosan azt csinálta, amit kértek tőle. Ráadásul többszöri futtatás után is azonos értelmezéshez jutott, vagyis a precizitás stabil, nem véletlenszerű szerencse terméke.
Meglepő az is, hogy a modellek hajlamosak voltak önellenőrzésre: a DeepSWE-nél a Claude Opus 4.7 és a GPT-5.4 a futásai több mint 80 százalékában írt és futtatott saját teszteket, annak ellenére, hogy erre senki nem kérte őket. A SWE-Bench Pro-n ugyanez a hajlam visszaesett, mert ott a prompt előre figyelmeztet, hogy ne változtassanak a tesztlogikán.
Mi jön most a kódolási benchmarkok világában?
A DeepSWE elismeri saját korlátait: minden változtatást Bash-en keresztül végez – nem natív szerkesztőeszközökkel, ahogy a modelleket tanították. Csak 500 csillagos, nyílt forráskódú repókból válogat, így lehet, hogy zárt kódokhoz nem lesz megfelelő. Kevés benne a hibakeresési és refaktorálási feladat, C++ és Java például kimarad. Az értékelést egy LLM végzi, nem ember, és a minták is korlátozottak.
Fontos, hogy a Datacurve maga is üzleti vállalkozás. Bár közzétették a teljes adathalmazt, az ügynökök útvonalait és az értékelő keretrendszert is, független ellenőrzésre szükség lesz, hogy a közösség elfogadja eredményeiket.
Az MI-kódírók piaca gyors átalakulásban van. A cégek dollármilliárdokat költenek ezekre az ügynökökre – azok minősítését azonban olyan benchmarkokra bízzák, amelyek akár harmadában is tévedhetnek. Bár mindenki abban hisz, hogy az MI a szoftvermérnökök munkáját veszi át, a valódi fejlődés és annak illúziója között csak egy hajszál a különbség – s most az egész iparág jövőjéről lehet szó.