Miért okoz gondot a finomhangolás?
Nem kizárt, hogy a fejlesztők körében elterjedt félreértés él arról, hogyan működik valójában a szemantikai alapú információvisszakeresés. A Redis kutatásai kimutatták, hogy ha egy beágyazó modellt úgy tréningeznek, hogy az jól felismerje a mondatok szerkezeti különbségeit – például azt, hogy a “A kutya megharapta az embert” és “Az ember megharapta a kutyát” egészen mást jelent –, akkor ezzel együtt jelentősen csökken a modell általánosítási képessége. Azaz a modell kevésbé lesz képes helyesen visszahozni információt olyan témákból, amelyekre eredetileg nem tanították be. Míg kisebb modelleknél a csökkenés csak 8-9%, egy közepes, jelenleg is élesben használt modell esetében elérte a 40%-ot. Ez azért veszélyes, mert a vállalati MI-folyamatok egész lánca épül a visszakeresés megbízhatóságára.
A beágyazó modellek korlátai
Ezek a modellek egy teljes mondatot egyetlen pontra redukálnak egy sokdimenziós térben, majd egy lekérdezésnél ehhez keresik a legközelebbi pontokat. Ez kiválóan működik, ha hasonló témákat és dokumentumokat kell összepárosítani, de csődöt mond, ha két, majdnem azonos szóhasználatú, ám ellentétes értelmű mondat között kell különbséget tenni. A szerkezeti különbségek ugyanis – például tagadás, szórend – gyakran elvesznek, mert a modellek inkább a szóhasználatra, mint a mondat szerkezetére fókuszálnak. Ha viszont a modellt arra képezzük ki, hogy ezeket a szerkezeti különbségeket meglássa, akkor éppen az általános visszakeresési képességek rovására történik az előrelépés. Ráadásul a pontatlanságok éppen azoknál a mondatszerkezeti hibáknál maradnak fenn, amelyek a legnagyobb gondot okozhatják, például szerződéses jogviszonyok esetében.
A megszokott megoldások kudarcai
Sokan próbálkoznak kulcsszavas kereséssel kombinált rendszert fejleszteni, de ezek az eljárások nem tudnak különbséget tenni hasonló szavakból álló, de eltérő jelentésű mondatok között – így például a “Róma közelebb van, mint Párizs” és “Párizs közelebb van, mint Róma” ugyanúgy esik áldozatul.
Az ún. MaxSim újrarangsorolás, ahol szavanként pontozzák a lekérdezést és a dokumentumokat, ugyan javítja az általános relevanciaértékeket, de továbbra is pontatlan marad, ha szerkezeti különbséget kell felismerni. A MaxSim ugyanis a hasonlóságot keresi, de teljesen vak a jelentésbeli különbségekre és viszonyokra.
A keresésbe bevont Cross-encoder megoldások, amikor az MI minden szót mindennel összehasonlít, kiválóan működnek laboratóriumi körülmények között, de valós, nagy lekérdezésszám mellett túl lassúak és drágák.
Az újabbnak számító agentikus, kontextuális memóriát alkalmazó rendszerek sem oldják meg a problémát, hiszen ők is alapvetően a visszakeresés során hibázhatnak.
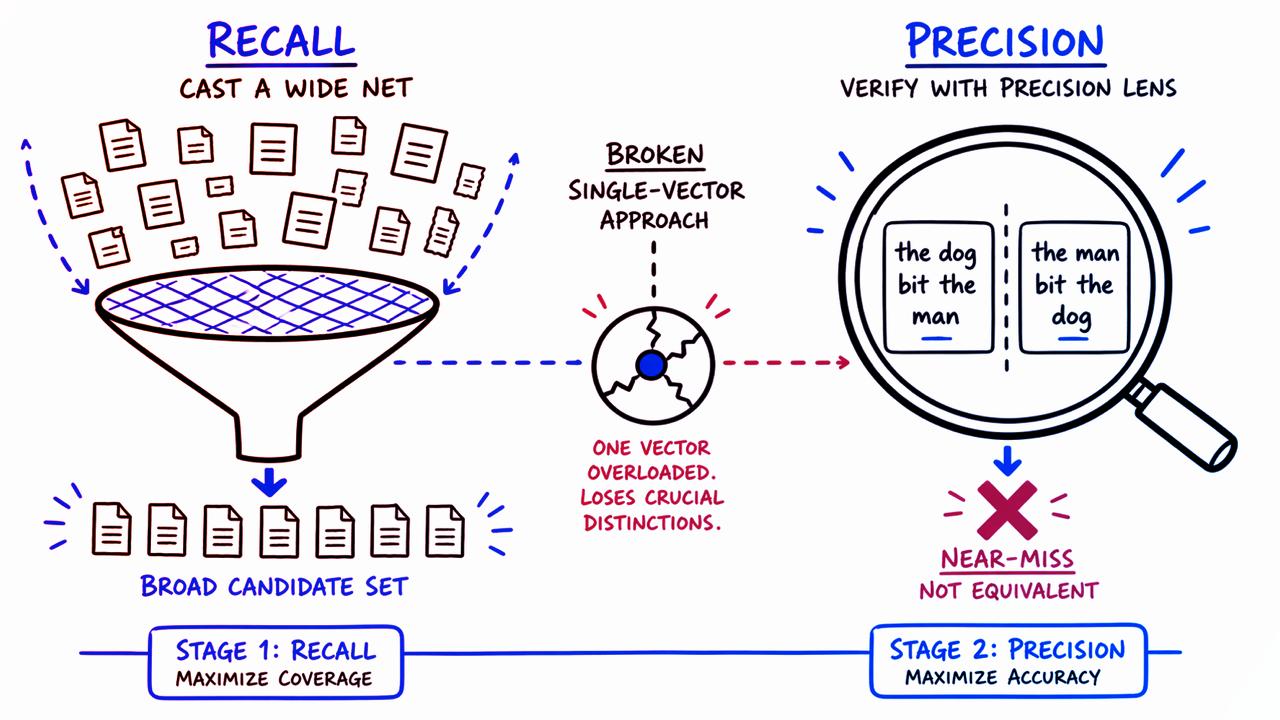
Kétlépcsős megoldás: előszűrés és megerősítés
Az egyetlen hatékony módszer a két szakaszból álló rendszer: az első szakaszban egy gyors, hagyományos beágyazó modell széles spektrumból visszahozza a legvalószínűbb találatokat. A második szakaszban egy kisméretű, tanított Transformer-modell minden egyes potenciális találatot token szinten, szóról szóra összevet a lekérdezéssel, hogy felfedje a szerkezeti eltéréseket. Ez az ellenőrző lépés az, amire a szimpla vektorkeresés nem képes.
A vizsgálatok szerint ez az új, kétlépéses architektúra megbízhatóbban szűrte ki a szerkezeti hibákat, mint bármelyik másik módszer. Igaz ugyan, hogy ezzel a módszerrel mindig kompromisszumot kell kötni: a második, ellenőrző szakasz extra késleltetést jelent. A késleltetés attól függ, mennyi találatot vizsgálunk így át: jogi vagy pénzügyi alkalmazásoknál minden lekérdezésnél szükséges lehet, általános keresésnél elég lehet a szűrt halmaz egy részét vizsgálni.
Tanulságok vállalatok számára
A jó hír, hogy a vállalatoknak nem kell teljesen újraépíteniük meglévő rendszerüket. Lényeges azonban, hogy a fejlesztők tisztában legyenek az MI-alapú visszakereső rendszerek valós viselkedésével, és ne dőljenek be a teszteredményeknek vagy általános benchmark-pontszámoknak. Rajamohan, a kutatás vezetője, három szempontot tart szem előtt: helyes válasz, teljesség és hasznosság. Ha valamelyikben hiba csúszik, az végiggyűrűzik a teljes rendszerben.
Szintén fontos megjegyezni, hogy maga a RAG-architektúra nem elavult, viszont a túlfinomhangolt, egyfázisú rendszerek önmagukban nem alkalmasak komolyabb, precíziós igényű vállalati munkára. A kétlépcsős modell valós megoldás, de mindenki számára egyértelmű kompromisszummal jár: a nagyobb pontosság extra időráfordítást jelent.