A Google saját, mintegy 20 milliárd videóból álló YouTube-gyűjteményét használja arra, hogy mesterséges intelligencia modelleket, például a Geminit és a Veo 3-at tanítsa videó- és hanggenerálásra. Egy, a témához közel álló forrás szerint a vállalat ezekből a YouTube-videókból merít, ugyanakkor hangsúlyozzák, hogy csak egy részhalmazt alkalmaznak, továbbá a tartalomkészítőkkel és médiacégekkel kötött megállapodásokat tiszteletben tartják.
Milliárdnyi perc, elképzelhetetlen mennyiség
Nyilvánosan nem közölték, pontosan hány vagy melyik YouTube-videót etetik be az MI-nek, de egyes becslések szerint, ha csak a teljes katalógus 1%-át használják fel, az 2,3 milliárd percnyi tartalmat jelent – ez több mint negyvenszerese annak a mennyiségnek, amelyre a rivális MI-rendszerek támaszkodnak.
Tisztázatlan részletek, nő az izgalom
A lépés számos kérdést vet fel a tartalomkészítők jogairól és a videók felhasználásának mértékéről. A Google továbbra is hangsúlyozza, hogy betartja a szerződésekben foglaltakat, miközben bővíti az MI képességeit, elképesztő méretű adathalmazokat használva fel mindenki számára.
2025, adrienne, tech.slashdot.org alapján
Legfrissebb posztok
MA 18:31
Az Európai Unióban évek óta tartó, elhúzódó versenyjogi harc végére került pont: a Google-nek rekordösszegű, 4,1 milliárd eurós bírságot kell kifizetnie...
MA 18:02
Július elsejétől a Medicare támogatja az új generációs GLP-1 testsúlycsökkentő gyógyszereket, már havi 50 dolláros (kb...
MA 17:31
A NetNut néven futó lakossági proxyhálózatot kemény csapás érte, amikor nagy technológiai cégek és az amerikai hatóságok együtt léptek fel az online bűnözés ellen...
MA 17:02
🔒 A PamStealer nevű, most felfedezett macOS-kártevő alaposan feladja a leckét az Apple gépeket használóknak...
MA 16:31
Több mint negyven évvel ezelőtt egy hatalmas állat gerincdarabját emelték ki az antarktiszi jég fogságából...
MA 16:02
Tipikus eset, amikor mindenki attól tart, hogy az MI elterjedése elveszi a munkahelyeket, de a számok mást mutatnak: az MI-re nagyban támaszkodó vállalatok valójában bővítik a munkatársi létszámot...
MA 15:32
🚀 Majdnem elképzelhetetlen, hogy ne hallottunk volna arról, mekkora sikert aratott a SpaceX a tőzsdére lépésével...
MA 14:31
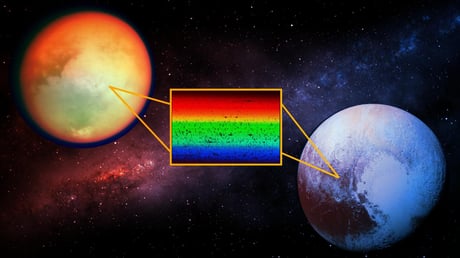
A James Webb űrteleszkóp legújabb megfigyelései szerint egy rejtélyes hullámhossz hiányzik a törpebolygó, a Plútó és a Szaturnusz legnagyobb holdja, a Titán felszínéről visszaverődő fény spektrumából...
MA 12:01
A Föld óceánjai idén júniusban történelmi hőmérsékleti rekordot döntöttek, ráadásul éppen akkor, amikor az El Niño hatása is felerősödik a Csendes-óceánon...
MA 11:31
A több mint öt évtizede érvényben lévő tiltás, amely megakadályozta a szuperszonikus utasszállítók áthaladását az Egyesült Államok városai felett, hamarosan a múlté lehet...
MA 11:01
🔥 Amerikát rendkívüli hőhullám sújtja, amely a középső és keleti régiókban éri el csúcspontját, és várhatóan egészen a függetlenség napjáig kitart...
MA 10:49
Elég csak egy ártatlannak tűnő linket behúzni a böngészőbe, és három másodperccel később már jogosulatlanul hozzáférhet valaki a Microsoft 365-fiókodhoz, miközben semmilyen szokványos biztonsági jelzés nem figyelmeztet előre a veszélyre...
MA 10:37
🦇 Egy 11 éves ontariói fiú tragikus körülmények között veszettségben vesztette életét, miután egy denevér éjszaka az arcán leszállt...
MA 09:49
Az Egyesült Államok kormánya új szintre emeli a földönkívüli élet utáni kutatást: külön tudományos tanácsadó testület segíti az ország vezetőit az azonosítatlan légköri észlelések, vagyis az UAP-ok vizsgálatában...
MA 09:24
A Meta új előfizetési rendszert vezet be az okosszemüvegeihez, amely érinti mind a Ray-Ban- és Oakley‑modelleket, mind a saját márkás eszközöket...
MA 09:14
💸 Egy lényeges szempont, hogy az amerikai kormány jelenlegi hiánya soha nem látott magasságokba emelkedett, miközben egyre élénkebb vita övezi a költségvetési reformok szükségességét...
MA 09:12
Fizetős iOS appok és játékok, amik ingyenesek a mai napon. FormatX: Video Audio Converter (iPhone/iPad)A FormatX egy sokoldalú, minden az egyben formátum átalakító eszköz, amely egyszerűen és gyorsan alakít át videó-, hang- és képformátumokat...
MA 09:02
Egyre látványosabb átrendeződés zajlik a fejlesztői eszközök piacán: Pekingből érkezik egy új szereplő, amely odacsap a veterán nyugati óriások asztalára...
MA 08:49
🔒 A Nest x Yale Lock hosszú időn át az egyik legismertebb okoszár volt a piacon, de most végleg eltűnt a Google Store kínálatából...
MA 08:03
Az elmúlt hét legnagyobb MI-híre Amerikában az volt, hogy visszavonták az Anthropic Mythos és Fable modelljeire két hete bevezetett exportkorlátozásokat...
MA 07:49
💎 Közel 46 ezer alkalmazott dolgozik a világ egyik legnagyobb pénzügyi intézményénél, ahol évente több mint egymillióan pályáznak állásra...
MA 07:37
Egy rejtélyes, ősi galaxis, az MXDFz4.4 fényét sikerült észlelni a világegyetem legkorábbi időszakából, ami eddig lehetetlennek tűnt...
MA 07:13
🚀 Senki sem várta volna, hogy a holdraszállásról álmodó NASA egyik legkomolyabb akadályát saját beszállítói okozzák, mégpedig a Blue Origin csúszásai miatt...
MA 07:01
🔥 A digitális vagyonkezelés újabb mérföldkőhöz érkezett: a BlackRock és az ARK Invest által is támogatott Securitize egyszerre lépett be a New York-i tőzsdére, és tokenizálta saját részvényeit...
MA 06:49
A Venezuelát múlt héten sújtó földrengések következtében a halálos áldozatok száma 2 595-re nőtt, miközben a mentőalakulatok továbbra is versenyt futnak az idővel a túlélők felkutatásáért...
MA 06:26
🚦 A luxushajón tavasszal felbukkanó hantavírus-járvány végre hivatalosan is lezárult. A fertőzés korábban három ember halálát okozta, és komoly félelmeket keltett a további terjedésével kapcsolatban...
MA 06:06
Viharos ütközetek, trónra lépések és technikatörténeti mérföldkövek jelölik ezt a napot: a gettysburgi csata tetőpontja, Hugh Capet francia királlyá koronázása és a Mallard gőzmozdony világrekordja egyszerre rajzolják át a történelem térképét...
MA 06:01
A Microsoft SharePoint-rendszerei újabb komoly biztonsági kockázattal néznek szembe: a legújabb, távoli kódfuttatást lehetővé tévő sérülékenységet már aktívan kihasználják a támadók...
csütörtök 18:31
Egy hétfő reggel Sarah Davies, egy nagy brit élelmiszergyártó pénzügyi vezetője, szokása szerint felhívta idős édesapját...