
Tag: nagy nyelvi modellek
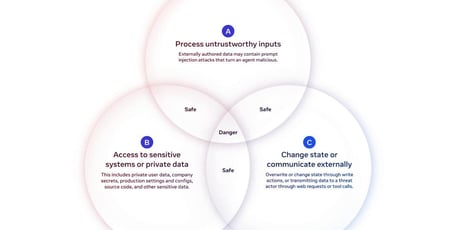
Az MI-ügynökök védelme még mindig gyenge
Az utóbbi időben két új, figyelemre méltó tanulmány is napvilágot látott a nagy nyelvi modellek (LLM) biztonságával és a prompt injection támadásokkal kapcsolatban....

Az MI már túlságosan engedékeny, meglepő a nyelvi modellek szervilizmusa
Lényeges hangsúlyozni, hogy a nagy nyelvi modelleknél (LLM) széles körben elterjedt a hajlam a felhasználók kritikátlan kiszolgálására, még akkor is, ha ez a...

Az MI rejtett elfogultsága miatt botrányos viták a vacsoraasztalnál
Az egyre szélesebb körben használt nagy nyelvi modellek (LLM-ek), mint például a GPT-5 vagy a Claude Sonnet, mind tartalmaznak valamilyen elfogultságot – és...

Claude 4 öntudatra ébred? Meglepő válaszokat adott a mesterséges intelligencia!
Az MI-alapú chatbotok már életünk minden területére beszivárogtak, legyen szó munkáról, tanulásról vagy szórakozásról. A Pew Research Center 2024-es felmérése szerint az amerikaiak...

Az Nvidia hibás MI-chipek titkos kínai útja
Hiába a szigorú amerikai exporttilalom, Kínában virágzik az Nvidia korlátozott MI-chipek javításával foglalkozó üzlet. Tizenkét, főként sencseni kisvállalkozás vállalja, hogy évente több tízezer,...

Az MI már önállóan szervez kibertámadásokat
A legújabb kutatások szerint a nagy nyelvi modellek (LLM-ek) nemcsak segítik a kiberbiztonságot, hanem lassan önálló hackerekké is válhatnak. Egy friss vizsgálatban MI-tesztalanyokat...