Ügynökök szabálya: csak kettőt a háromból!
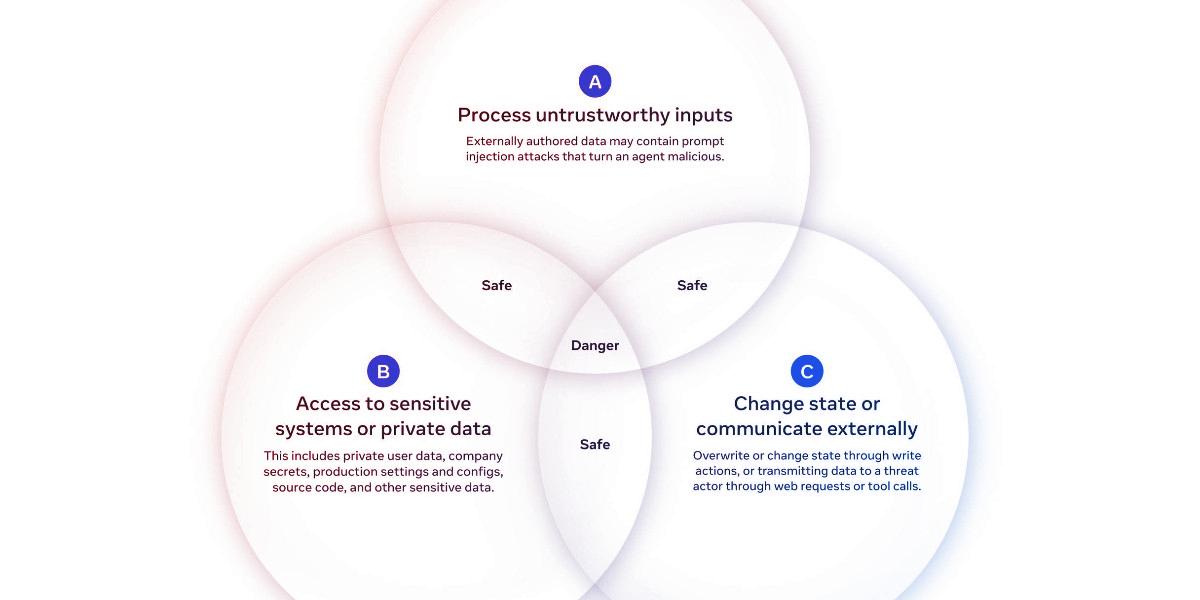
A Meta új tanulmánya, az Agents Rule of Two (Az ügynökök kettőszabálya) nagyon tömören foglalja össze, hogyan lehetne csökkenteni a prompt injection támadások legsúlyosabb következményeit. Eszerint egy MI-ügynök egy adott munkamenet során legfeljebb két kritikus tulajdonsággal rendelkezhet a háromból: feldolgozhat megbízhatatlan bemeneteket, hozzáférhet érzékeny adatokhoz vagy rendszerekhez, illetve képes lehet állapotváltozást előidézni vagy külső kommunikációt folytatni. Lényeges hangsúlyozni, hogy ha egy ügynöknek mindhárom képességre szüksége van, tilos teljes autonómiával működnie, és legalább emberi felügyeletet igényel.
Ez a megközelítés üdítően egyszerű: a korábbi, lebilincselő hármas például főként csak az adatlopás veszélyére vonatkozott, míg az új szabály a rendszerállapot-módosítás kockázatát is figyelembe veszi. Ettől függetlenül a modellnek van némi korlátja is: a szerzők szerint a megbízhatatlan bemenetek és az állapotváltoztatás kombinációja sem biztonságos, még ha nincs is hozzáférés érzékeny adatokhoz – de e kitétel bevezetése már rontaná a hasznos egyszerűséget.
A támadó mindig egy lépéssel előrébb jár – és átjut a védelmen
Egy másik, még nagyobb visszhangot kiváltó tanulmány 14 neves szerzőtől – köztük az OpenAI-tól, a Google DeepMindtól és az Anthropictól – 12 publikus védelmet, köztük prompt injection és jailbreaking elleni módszert vetett vizsgálat alá. A kutatók úgynevezett adaptív támadásokat alkalmaztak: a támadó algoritmusok vagy emberek többször próbálkozhattak, miközben figyelték a rendszer reakcióit, és menet közben fejlesztették stratégiájukat.
Az eredmény: a vizsgált védelmek túlnyomó többsége elbukott, sokszor több mint 90%-os sikeraránnyal törték át őket. Lényeges, hogy humán tesztelés során – egy 7,4 millió forintos verseny keretében, 500 résztvevővel – minden védelem megadta magát. Ez rávilágít arra, mennyire illuzórikusak a statikus, egyszeri trükkökkel tesztelt védelmek: az adaptív, folyamatosan fejlődő támadások könnyedén túljárnak rajtuk.
Az ellen-védekezés csapdája: minden támadás egyéni válaszokat követel
A támadók több fő módszert is hatékonyan alkalmaztak: a gradiensalapú optimalizációt, a megerősítéses tanulást, de legfőképp a keresésalapú megközelítések bizonyultak eredményesnek. Ez utóbbinál a támadók MI-t használtak arra, hogy támadószövegeket generáljanak, majd MI-alapú minősítési rendszeren szűrték át azokat. Ettől függetlenül még a fejlettebb algoritmusoknál is a humán tesztelők jeleskedtek a leghatékonyabb támadásokban.
A kutatók óvatos optimizmussal fogalmaznak: szerintük az adaptív tesztelés bonyolultabb, de elengedhetetlen, és bíznak benne, hogy az ilyen tesztek emelik majd a védelmek színvonalát. Összefoglalásként megjegyezhető, hogy az új szabályok és felismerések fényében továbbra sincs megbízható, univerzális védelem a prompt injection támadások ellen – az egyetlen járható út az, ha a kettőszabály szerint kialakított rendszerekben eleve korlátozzuk az MI-ügynökök lehetőségeit, és nem hagyjuk, hogy autonóm módon mindhárom kritikus képesség összetalálkozzon egyetlen munkamenetben.