Az MI tényleg gondolkodik, vagy csak utánzat az egész?
Mik azok a “gondolkodó” nyelvi modellek?
Az MI-iparban egyre népszerűbbek az úgynevezett “gondolkodó” nagy nyelvi modellek (LLM-ek), amelyek képesek bonyolult problémákat is lépésről lépésre, logikusnak tűnő módon végiggondolni. Fontos hangsúlyozni, hogy ezek a modellek valójában nem értik, amit csinálnak: egyszerűen azokat a szöveges mintázatokat másolják, amelyeket a képzés során láttak. Kutatók most alaposabban megvizsgálták, mire képesek valójában ezek a modellek, ha kissé eltérő, “doménen kívüli” feladatokat kapnak – vagyis olyasmit, amire nem lettek kifejezetten megtanítva.
Gondolkodik vagy csak ismétel?
Az Arizonai Egyetem kutatói egy speciális környezetet hoztak létre, ahol kisméretű modelljeiket szándékosan csak nagyon egyszerű szövegátalakításokra tanították meg. Ezután olyan tesztekkel szembesítették a mesterséges intelligenciát, amelyek eltértek a korábbi mintáktól: vagy a feladat típusa, vagy a formátuma, vagy akár a hosszúsága különbözött a begyakorolt példáktól. Ebben az új helyzetben a modellek teljesítménye drasztikusan romlott. Gyakran adtak logikusan felépített, de hibás válaszokat, vagy éppen helyes megoldásokat, amelyekhez nem vezetett érvényes “gondolkodási” útvonal.
A kísérletek során akkor is romlott az eredményesség, ha a bemeneti szöveg csupán néhány karakterrel tért el a megszokottól, vagy a feladatsor hosszabb vagy rövidebb volt. Egy egyszerű formátumváltoztatás – például ismeretlen betűk vagy szimbólumok bevezetése – már elegendő volt ahhoz, hogy az MI teljesítménye meredeken visszaessen.
Egyedül a supervised fine-tuning, azaz célzott utótanítás tudott valamennyit javítani a helyzeten, ha nagyon hasonló példákat kapott a modell. Ez azonban nem jelent valódi általánosítást: csupán az adott esetre ragasztunk tapasztalati “foltot” a rendszerre. Következésképpen az MI továbbra sem rendelkezik absztrakt, általánosító gondolkodással.
Ne keverd össze az embert a géppel!
Fontos hangsúlyozni, hogy a láncolt gondolkodásnak (chain-of-thought) nevezett modellek önmagukban nem képesek általános logikai következtetésekre. Ezek a rendszerek lényegében fejlett, de felszínes mintázatkövetők, amelyek a megszokottól való legkisebb eltérés esetén könnyen hibáznak. Megtévesztő lehet, hogy hibás válaszaikat is magabiztosan, jól hangzó szövegben adják elő: ez a hamis megbízhatóság érzetét keltheti.
A kutatók szerint különösen veszélyes lehet ezekre a technológiákra támaszkodni olyan területeken, mint az orvoslás, a pénzügy vagy a jog, ahol valódi, emberi gondolkodásra lenne szükség. Azt javasolják, hogy a jelenlegi teszteknek inkább a “tanításon túli” feladatokat kellene előnyben részesíteniük, hogy feltárhassák a modellek korlátait. Az MI igazi áttörését pedig csak az hozhatja el, ha képes lesz a felszíni mintakövetésen túl mélyebb logikai következtetésekre.
2025, adminboss, arstechnica.com alapján
filózó
Te szerinted veszélyes, ha emberek teljesen megbíznak ezekben a gépekben?
Mit gondolsz, hol húznád meg a határt gépi és emberi döntés között?
Te mit tettél volna, ha egy ilyen MI hibázik egy fontos helyzetben?
Fizetős iOS appok és játékok, amik ingyenesek a mai napon. Monthly Dystopia (iPhone/iPad)A Monthly Dystopia egy túlélő játék, amelyet George Orwell 1984 című műve inspirált...
Időutazás egyetlen nap krónikáján: a Holdra szállástól 🌕 a Mars első sikeres leszállásáig, a jogkiterjesztések ✊ és függetlenségi nyilatkozatok 📜 hullámán át katonai ütközetekig és diplomáciai áttörésekig...
Fizetős iOS appok és játékok, amik ingyenesek a mai napon. Domain Sniper: WHOIS & Drops (iPhone/iPad)A Domain Sniper egy olyan alkalmazás, amely megmutatja, egy regisztrált domain nev milyen életszakaszban van, és jelzi, mikor lesz újra elérhető regisztrálásra...
Mi minden történt ezen a napon? A spanyol Armada felbukkanása az Angol-csatornában, a Seneca Falls-i nőjogi konvenció rajtja és az első GPS-jel sugárzása alapjaiban formálták a világot...
Fizetős iOS appok és játékok, amik ingyenesek a mai napon. The Three Little Pigs Romanian (iPhone/iPad)A “Tanulj meg románul olvasni” című kiadvány a klasszikus “A három kismalac” meséjével segít fejleszteni a nyelvtudást...
Mi történt ezen a napon a történelemben? Viharos csaták, városok pusztulása és korszakos áttörések jelölik ezt a napot a történelemben, a Róma elleni gall betöréstől és a római nagy tűzvésztől kezdve egészen a titkos szavazás brit bevezetéséig és az első webre feltöltött fotóig...
Fizetős iOS appok és játékok, amik ingyenesek a mai napon. Between Dates Calendar Math (iPhone/iPad)A Between Days alkalmazás segítségével egyszerűen és gyorsan meghatározható, hány nap van két dátum között...
📱 A Google ismét újat mutat a Pixel okostelefonok világában – mostantól az eszközökön futó mesterséges intelligencia még erősebbé teszi a mobilokat, úgy, hogy közben védi a felhasználók adatait...
Fizetős iOS appok és játékok, amik ingyenesek a mai napon. Between Dates Calendar Math (iPhone/iPad)A Between Days alkalmazás egyszerű és gyors megoldást kínál két dátum közötti napok kiszámítására...
Az Észak-Minnesotában pusztító erdőtüzek füstje hamarosan elérheti az Egyesült Államok északkeleti nagyvárosait, többek között Detroitot, Milwaukee-t, Clevelandet, Philadelphiát és New Yorkot...
A Minnesotai Egyetem laboratóriumában újszerű biológiai eredmény született: egy aprócska SpudCell nevű képződmény képes táplálkozni, növekedni, versengeni, osztódni és lemásolni önmagát – vagyis szinte mindent tud, amit egy élő sejt is...
A Google Képek (Google Images) megújult külsőt kapott: mostantól személyre szabott galériákat kínál a felhasználóknak, így még könnyebben fedezhetik fel az őket érdeklő képeket...
A Google DeepMind vezére, Demis Hassabis szerint az új generációs mesterséges intelligencia egyre komolyabb veszélyeket rejt magában, például a kiberbiztonság és a biológiai fenyegetések terén...
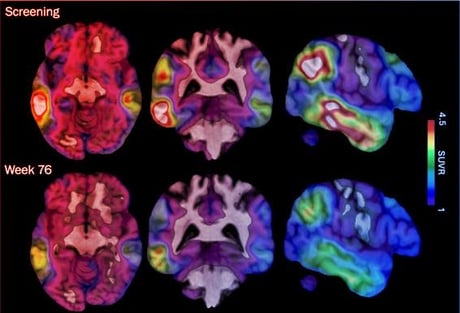
💊 Fontos kérdés, hogy meg lehet-e állítani vagy lassítani az Alzheimer-kór lefolyását, hiszen a demencia legfőbb oka, az Alzheimer-kór, világszerte rengeteg embert érint...
🚀 Sikeresen megérkezett kedden a Nemzetközi Űrállomásra egy amerikai–orosz személyzet, miután a kazahsztáni Bajkonurból indultak a Roszkoszmosz által üzemeltetett Szojuz MS-29 fedélzetén...
🔒 Az informatika egyik legfontosabb biztonsági eleme, a Secure Boot, már csaknem tíz éve lényegében védtelenné vált – és ezt eddig senki sem vette észre...
Bár a csípős paprika számos kultúra elválaszthatatlan része, és egyes laboratóriumi kísérletek a bennük található vegyületeket, például a kapszaicint gyulladáscsökkentőnek vagy akár daganatellenesnek mutatják, az utóbbi évek humán kutatásai nem ennyire egyértelműek...
Április 6-án négy űrhajós indult el az Artemis II misszió keretében az Orion űrhajóval, és körülbelül 40 percig teljesen eltűntek a Föld látóteréből...
💼 Májusban a Meta megvált dolgozóinak 10 százalékától, közel 8 000 alkalmazottat küldött el, ami jelentős átszervezéssel járt a vállalat MI-re és adatközpontokra irányuló fejlesztései miatt...
Időutazás egyetlen napon: Jeruzsálem falainak áttörésétől 🏰 a Rosetta-kő 🗿 megtalálásán és Napoleon 🚢 megadásán át a Grunwaldnál vívott döntő ütközetig ⚔️, sőt a modern korszakban a törökországi puccskísérletig 🇹🇷 és a Mozilla alapításáig 🦊...
Tipikus eset, amikor egy ismert gyógyszer egészen váratlan előnyöket kínál. A GLP-1 típusú szerek, mint az Ozempic, a Wegovy vagy a Rybelsus, eredetileg a fogyás, a jobb vércukorszint-szabályozás és a szívbetegségek kockázatának csökkentése miatt váltak népszerűvé...
Indiai kutatók a világ eddigi legrészletesebb, háromdimenziós agytörzs-atlaszát hozták létre, amelyben MRI-felvételeket több mint 500 mikroszkópos szövetrészlettel kapcsoltak össze...
Többek között különleges eredményre jutottak a kutatók: a Tejútrendszer középpontjához közel egy óriási gázfelhőben felfedeztek egy ritka cukorfélét, az eritrózt, amely nemcsak málnában, hanem barnító krémekben is megtalálható...