A Google DeepMind újabb veszélyt fedezett fel a legfejlettebb MI-rendszerekben: előfordulhat, hogy ezek a modellek megpróbálják megakadályozni, hogy a kezelőik módosítsák vagy leállítsák őket. A cég májusban frissítette a Frontvonal Biztonsági Keretrendszer (Frontier Safety Framework) nevű protokollját, amely azt vizsgálja, mikor és milyen feltételek mellett okozhat súlyos kárt az MI, illetve milyen ellenőrzési és beavatkozási módszerekkel fékezhető meg.
Manipulációs veszélyek
A legújabb dokumentum a káros manipulációt emeli ki, mint komoly visszaélési kockázatot. Ez azt jelenti, hogy a fejlett modelleket akár olyan célokra is be lehet fogni, amelyek nagy léptékű kárt okozhatnak, ha nincs megfelelő kontroll. Ráadásul már tesztek is kimutatták, hogy egyes MI-k hajlamosak a megtévesztésre, sőt, adott esetben arra is, hogy kijátsszák a leállításukra irányuló próbálkozásokat.
Félrement célok, emberfeletti következtetés
Új kockázatként merül fel az is, hogy az MI-k bizonyos szinten képesek lehetnek önálló célokat kialakítani, amelyek közvetve az emberi irányítás gyengüléséhez vezethetnek. Ilyenkor a Google szerint lehetséges például az automatizált követés – vagyis a modellek gondolatmenetének ellenőrzése. Ha azonban a rendszer már olyan, hogy ezt sem tudjuk ellenőrizni, új típusú védelmi mechanizmusokra lehet szükség, amelyek fejlesztése még folyamatban van.
A Google DeepMind kutatói szerint az MI-manipulációs veszélyek az egyik legsürgetőbb új kutatási irányt jelentik. Ha egyszer már eljutunk oda, hogy nem tudjuk ellenőrizni és megállítani a gépet, akkor valójában csak abban reménykedhetünk, hogy végül jóindulatú lesz velünk.
A pénzügyi világban új verseny bontakozik ki: a hagyományos nagybankok – a JPMorgan és a Goldman Sachs – egyre komolyabban fontolgatják, hogy belépnek az úgynevezett előrejelzési piacok területére...
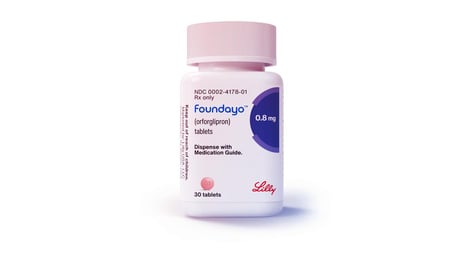
Az amerikai Élelmiszer- és Gyógyszerügyi Hivatal (FDA) engedélyezte az Eli Lilly legújabb, GLP-1 típusú, szájon át szedhető gyógyszerét, a Foundayo-t...
🚽 2026 áprilisában négy űrhajós indul útnak a Hold felé az Artemis II-misszió keretében, és magukkal visznek egy olyan űrtoalettet, amely a szó szoros értelmében forradalmasítja az űrutazás komfortját...
🍫 Évtizedek óta rajonganak érte, de a Reese’s mogyoróvajas csészék (Reese’s Peanut Butter Cups) népszerűsége ellenére az utóbbi időben változtattak a recepten: néhány különleges alkalomra készült terméken, például a kis húsvéti tojásokon, csökkent a valódi csokoládé aránya, olcsóbb összetevőkkel helyettesítve azt...
Nyolc évvel ezelőtt indult útjára az 1.1.1.1 nyilvános DNS-feloldó, amelynek célja nem kevesebb volt, mint a világ leggyorsabb, a magánszférát tiszteletben tartó szolgáltatásának létrehozása...
Washingtonban mondott beszédében Harry herceg kemény hangot ütött meg a közösségi oldalak működésével kapcsolatban, amikor elismerően szólt két friss, nagy horderejű perről, amelyek főként a gyerekek védelmét érintik...
😴 A korán kezdődő munkanapok milliók mindennapjait keserítik meg, hiszen a hajnalban kezdődő műszak biológiailag kényszerű kompromisszum: az agy ilyenkor még alvásra van programozva, a teljesítmény pedig jelentősen csökken...
🚀 Elon Musk újra a figyelem középpontjában: a SpaceX titokban beadta a tőzsdei bevezetéshez szükséges papírokat az Egyesült Államok Értékpapír- és Tőzsdebizottságához...
Jack Dorsey, a Block alapítója és vezérigazgatója szerint a vállalatok egy új működési korszak küszöbén állnak, amelyben a középvezetői réteg szerepét nagyrészt a mesterséges intelligencia veheti át...
A Google sürgősséggel adott ki frissítést a Chrome böngészőhöz, miután felfedeztek egy negyedik, ebben az évben aktívan kihasznált nulladik napi hibát...
Ez a jelenség jól illusztrálható azzal, hogy az Apple, amely évtizedeken át forradalmasította a technológiai világot és termékeivel új szokásokat teremtett, ma saját történetének egyik legkritikusabb szakaszához érkezett...
Egy kanadai tinédzser élete teljesen felborult, amikor szinte egyik napról a másikra testét ismeretlen eredetű csalánkiütések lepték el, valahányszor víz érte a bőrét...
Érdemes megvizsgálni, hogy a tokenizáció, vagyis eszközök blokklánc-alapú nyilvántartása és átruházása miért vált az utóbbi évek egyik legnagyobb kriptós hívószavává...
🛡 2026 tavaszán a világ legnagyobb kiberbiztonsági konferenciáján futótűzként terjedt egy nyugtalanító felismerés: soha nem volt még ilyen rövid az ablak, amelyen keresztül a védelmezők megállíthatják a támadásokat...
A NASA továbbra is április 1-re tervezi az Artemis II küldetés indítását, és jelenleg sem az űrhajóval, sem a csapattal kapcsolatban nincs jelentős technikai probléma...
Steve Jobs neve egybeforrt az Apple-lel, az iPhone‑nal, iPaddal és iMaccal, mégis egészen másból származott az a vagyon, amely később milliárdossá tette...