Intelligencia: Kik az MI-zsenik?
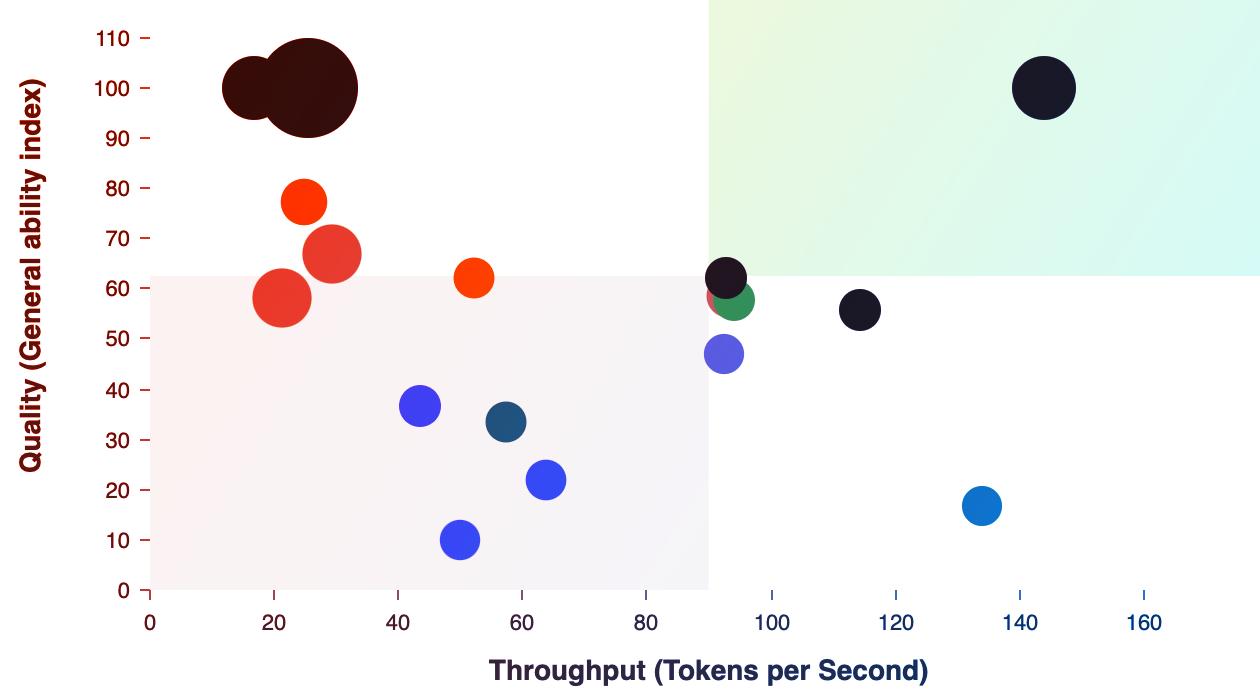
Az MI intelligencia-mutatója szerint jelenleg a Grok 4 és az o3-pro modellek uralják a mezőnyt, 68-as értékkel. Közvetlenül mögöttük a Grok o3 és az o4-mini (mindkettő szintén magas pontszámmal), valamint a Google Gemini 2.5 Pro következik. Érdemes megjegyezni, hogy a piac legdrágább modelljei között nem feltétlenül a legokosabbakat találjuk – a Grok 4 például 68-as intelligenciaszámmal 2,7 millió Ft/1M token áron kapható.
Ezzel szemben akadnak olyan modellek is, amelyek alacsonyabb áron kínálnak figyelemre méltó teljesítményt: a DeepSeek R1, a GLM-4.5 vagy éppen a Qwen3 sorozat bizonyos verziói már 420–450 Ft/1M token áron elérhetők, mégis hasonló (55–60 körüli) intelligencia-mutatót produkálnak.
Kiváló ár-érték arányt kínál a gpt-oss-20B (high) is, amely alig több mint 40 Ft/1M token áron 51 pontot ér el, bőven a középmezőny fölött.
Sebesség és válaszidő: Villámgyors MI-k
Az output sebességét tekintve toronymagasan vezet a Gemini 2.5 Flash-Lite (Érvelés / Reasoning), amely közel 500 token/másodperc tempót hoz – ez kétszerese a gpt-oss-20B (high) sebességének (386 token/másodperc), ami szintén kiemelkedő. Ezt a tempót csak néhány modell, például a Nova Micro, a GLM-4.5-Air vagy a Gemini 2.5 Flash-Lite közelíti meg.
A válaszadási késleltetés (tehát milyen gyorsan kapod az első választ) bajnokai is lenyűgöző eredményt mutatnak: az Aya Expanse 8B (0,14 mp!) és a Command-R (0,15 mp) szinte azonnal reagálnak, míg a LFM 40B és az Aya Expanse 32B is 0,16 mp körül indít. Ez alapján arra lehet következtetni, hogy a sebesség és késleltetés terén főleg a kisebb modellek, illetve a kifejezetten gyorsaságra optimalizált verziók a nyerők.
Árak: Hol a legolcsóbb a token?
Az áraknál jelentős eltérések láthatók. A legalacsonyabb ár, mindössze kb. 13 Ft/1M token, a Gemma 3 4B és a Gemma 3n E4B esetében érhető el – ráadásul egészen jó (14–18-as) intelligenciaérték mellett. Ez váratlanul jó ajánlat azoknak, akiknél a mennyiség fontosabb, mint a minőség.
Szintén meglepően olcsók a Llama 3.2 3B vagy a Mistral 3B, amelyek 15–16 Ft/1M token áron futnak, miközben egyes verzióik egész jó sebességet is hoznak. Ezzel szemben néhány, magas intelligenciájú modell, például az o3-pro vagy a Claude 4 Opus Thinking extrém drágák (akár 16 millió Ft/1M token), cserébe viszont kiemelkedő pontszámmal rendelkeznek.
Kontextusablak: Mekkora szövegre emlékszik?
A kontextusablak (memóriakapacitás) terén is vannak óriások: a Llama 4 Scout egészen elképesztő, 10 millió tokenes ablakot kezel, míg a MiniMax-Text-01 is eléri a 4 milliós határt. Az összes jelentős fejlesztő (Google Gemini, OpenAI, Mistral, Anthropic stb.) kínál már legalább 128 ezer tokenes vagy annál nagyobb memóriájú MI-t. Ez főleg azoknak kedvez, akik nagyon hosszú dokumentumokat vagy összetett feladatokat szeretnének egyben feldolgoztatni.
Kínálat: Óriási a választék – mindenki versenyben
Manapság már nemcsak az OpenAI, a Google vagy a Meta szerepel a mezőnyben: ott van a DeepSeek, Anthropic, Mistral, NVIDIA, IBM, Amazon, Apple, ByteDance vagy éppen a Xiaomi is. Közülük sokan saját, nyílt forráskódú vagy vállalati megoldásokat kínálnak, és külön modelleket fejlesztenek általános, kódolási, képfeldolgozó vagy multimodális felhasználásra.
A jelenlegi LLM-mezőny tehát elképesztően széles: a szuperszonikus sebességre vagy válaszidőre optimalizált modellektől a hatalmas memóriakapacitású vagy filléres megoldásokig rengeteg lehetőség közül lehet választani. Jelentős, hogy egyre több kisebb cég, sőt, teljesen nyílt forráskódú projekt is be tud kerülni a top modellek közé, meglepően jó eredményekkel.
Összegzés: Melyik MI-t válaszd?
Ha az abszolút intelligencia számít, leginkább a Grok 4, az o3-pro vagy a Gemini 2.5 Pro lehet a befutó, de érdemes figyelni az árakat is, hiszen néhány gyorsabb, olcsóbb modell akár sokkal jobb ár-érték aránnyal működik, például a Gemma 3 4B vagy a GLM-4.5. Sebesség és késleltetés terén inkább a könnyített, optimalizált modellekre érdemes fókuszálni; nagyobb dokumentumokhoz pedig az extrém kontextusablakkal rendelkezők ajánlottak. Mindezek alapján az MI-használat jövője jóval differenciáltabb lesz: a különböző igényekre – gyorsaság, ár vagy intelligencia – mindig más modellek kínálhatják a legjobb választ.