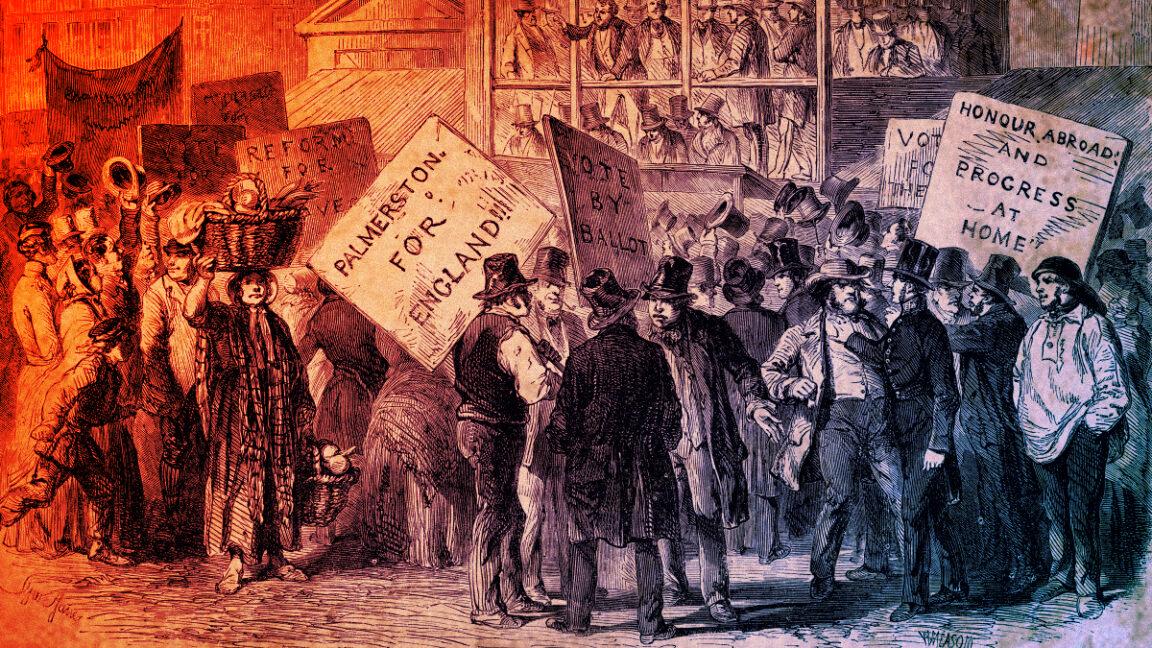
Viktoriánus hang galambszürke MI-től
Grigorian célja az volt, hogy megalkossa a TimeCapsuleLLM nevű modellt, amely kizárólag 1800 és 1875 között kiadott londoni szövegekből tanul, így hűen visszaadja a korra jellemző stílust, szóhasználatot és retorikai túlzásokat. A modell egyébként viszonylag kicsi, mindössze 6,25 GB-nyi adat alapján lett betanítva, szemben a korszerű, több száz gigabájtból tanuló rendszerekkel.
Érdemes megjegyezni, hogy más kutatók is építettek már hasonló, „időutazós” modelleket: például olyan MI-t, amely több mint 11 000, 1400 és 1700 között keletkezett szöveg alapján a 17. századi világnézetet tükröz bármilyen témában, vagy egy kínai MI-t, amely hagyományos költészeti szabályokat követve ír verseket.
“Véletlenül” igazi történelmi események
Grigorian egyszerű teszttel próbálkozott: beírta a modellnek, hogy „Az Úr 1834. évében…”, majd hagyta, hogy az folytassa. Az MI meglepően pontos korrajzot alkotott: London utcáit tüntetések és petíciók töltötték meg, mindezt Lord Palmerston tevékenységei kapcsán – pedig Grigorian a beállítások során sosem tanította külön erre az eseményre a modellt. Amikor utánanézett, kiderült, hogy valóban voltak tiltakozások 1834-ben a szegénytörvény-módosítás miatt; Palmerston ekkor külügyminiszter volt, később pedig brit miniszterelnökké választották.
Mégis, a technológiai közösség számára nem az a legmeglepőbb, hogy egy MI-modell egymáshoz nem kapcsolódó töredékekből koherens történetet alkot, hanem hogy ezt ilyen kis erőforrásból, egyetlen fejlesztő képes megvalósítani.
A „Szelektív időbeli tanítás” eredményei
Grigorian egy teljesen saját fejlesztésű módszerrel dolgozik, amelyet „Szelektív időbeli tanításnak” (Selective Temporal Training, STT) nevezett el – modern kifejezéseket automatikusan kiszűr, kizárólag 19. századi forrásokból dolgozik. A modellezés során egyedi tokenizálást alkalmaz, így a szavakat a legfontosabb szerkezeti elemeikre bontja. Az első verzió (mindössze 187 MB adatmennyiséggel) érthetetlen, viktoriánus utánzatot produkált, míg a jelenleg 700 millió paraméterből álló, bérelt A100-as GPU-n edzett változat már döbbenetesen korhű referencia-említésekkel szolgál.
Az MI-modellek növekvő adatmennyiségének és minőségének köszönhetően Grigorian szerint csökken a „fantáziálás”, vagyis a nem létező tények gyártása. Még előfordulnak valótlanságok, de a történelmi mintázatok, szereplők lassan „felidéződnek” a tanult adatbázisból.
Digitális múltidézés – világszerte
Az ilyen projektek nemcsak technológiai érdekességnek számítanak, hanem a történészek és bölcsészek számára is hasznosak lehetnek. Egy ilyen interaktív MI-modell lehetővé teszi, hogy a kutató egy letűnt korszak beszélőjével „beszélgessen”, vagy a régies szóhasználatot, mondatszerkesztést tanulmányozza.
Megemlítendő, hogy Grigorian a jövőben más városokra – például kínai, orosz vagy indiai történelmi modellekre – is szeretne MI-t fejleszteni, és szívesen működik együtt más kutatókkal is. Fejlesztéseinek kódját, súlyállományait és dokumentációját szabadon elérhetővé tette a GitHubon.
A múlt igazsága – véletlenül MI-től
Mindezek fényében a modern MI-fejlesztések világában – ahol mindennaposak az úgynevezett „hallucinációk” –, meglepő frissességgel hat, amikor egy modell a véletlen folytán éppen valós történelmi eseményt idéz fel. Szinte ironikus, hogy egy „factcident”, azaz „ténybaleset” vezet el a digitális időutazás új korszakához.