Az MI titkos szövetségese: a Common Crawl és a fizetős cikkek
A Common Crawl nevű nonprofit szervezet már több mint tíz éve milliárdnyi weboldalt gyűjt össze, hogy hatalmas internetarchívumot hozzon létre tudományos kutatások számára. Az utóbbi években azonban ez az adatbázis egyre vitatottabb célokat szolgál: olyan MI-fejlesztők, mint az OpenAI, a Google, az Anthropic, az Nvidia, a Meta és az Amazon használják modelljeik betanításához.
Fizetős cikkek titkos hasznosítása
A Common Crawl nemcsak a nyilvános internetet menti le, hanem a nagy hírportálokról származó, fizetőfal mögé rejtett cikkeket is, amelyekhez normális esetben csak előfizetéssel lehet hozzáférni. Ezekhez a tartalmakhoz a webes lementő egy programozási trükk segítségével jut hozzá: letölti a teljes szöveget, mielőtt az oldal ténylegesen lezárná azt az előfizetők számára. Így az MI-fejlesztők ingyen juthatnak hozzá a minőségi újságíráshoz, majd ezeket felhasználva készítenek híreket összegző vagy parafrazáló modelleket, amelyekkel végső soron épp a szerzőktől és kiadóktól vesznek el olvasókat és bevételeket.
Kereken tagadják a vádakat
A Common Crawl hivatalosan azt állítja, hogy csak szabadon elérhető tartalmakat ment le, nem mászik át fizetőfalakon, és készséggel eltávolít bármilyen tartalmat, ha a kiadók ezt kérik tőle. Ugyanakkor a gyakorlatban ez nem igaz: a letöltött fizetős cikkek mind a mai napig megjelennek MI-modellek tanítóanyagában, annak ellenére, hogy több kiadó kifejezetten kérte eltávolításukat.
Az alapítvány vezetője, Rich Skrenta szerint ha valami az interneten van, akkor bárki hozzáférhet – szerinte az MI-modelleknek is joguk van olvasni, mint bárki másnak. Véleményét azzal védte, hogy a kiadók is nyilvánossá tették anyagaikat azon az áron, hogy az MI-robotok is elolvashatják azokat. Eközben a Common Crawl botja, a CCBot ma már a világ első 1000 leglátogatottabb oldalát is rendszeresen feltérképezi, a háttérben pedig tovább pumpálja a minőségi, gyakran fizetős tartalmat az MI-fejlesztőknek. Az MI-modellek elképesztő fejlődése nagyban köszönhető a Common Crawl archívumának – a GPT-3-at például főleg ezekből az adatokból fejlesztették, ami 2022-ben végül a ChatGPT (Csevegő MI) alapját is adta.
👌 Most kapaszkodj meg, mert a Pixel 9a-val kapcsolatban végre jó hír érkezett: egyeseknél már megjelent a kikapcsolt képernyő mellett is működő ujjlenyomatos feloldás opciója...
💸 Ahogy a kriptovaluták egyre inkább belépnek a hagyományos pénzpiacokra, a nagy pénzügyi cégek is igyekeznek valamilyen módon jelen lenni ebben a világban...
Noha a Marsot általában kihűlt, halott világnak tartottuk, új bizonyítékok szerint a Tharsis nevű vulkánvidék mélyén komoly aktivitás zajlik, amely a bolygó forgását is felgyorsíthatja...
A zenei platform elindította az Artist Profile Protection nevű opciót, amellyel a zenészek megelőzhetik, hogy véletlenül vagy szándékosan rossz profilokra kerüljenek fel a zenéik...
Na most kapaszkodj, mert a Bandsintown végre teljes erőbedobással összeborult az Apple-lel: mostantól már az Apple Musicban is böngészheted kedvenc előadóid közelgő koncertjeit...
Az internetes szólásszabadság ma egyre komolyabb veszélyben van. Számos ország kormányai mindent elkövetnek azért, hogy megakadályozzák lakosaikat az internet szabad használatában: nemcsak egyes oldalakat, hanem alapvetően magát a világhálót próbálják elérhetetlenné tenni...
🔒 A Firefox legújabb, 149-es verziója egy teljesen új szintre emeli a böngészés biztonságát: a beépített, ingyenes VPN-funkcióval immár havi 50 GB adatforgalmat kap minden Mozilla-fiókkal rendelkező felhasználó...
A Gap Inc., amelyhez olyan divatmárkák tartoznak, mint az Old Navy, a Gap, a Banana Republic és az Athleta, lehetővé teszi, hogy a vásárlók közvetlenül a Google Gemini alkalmazásán keresztül fejezzék be vásárlásaikat – anélkül, hogy elhagynák a platformot...
Az Egyesült Államokban több mint 3200 iskolai körzetben használt Infinite Campus digitális diáknyilvántartó rendszert adatlopás érte, miután hackerek egy alkalmazott Salesforce-fiókjához fértek hozzá...
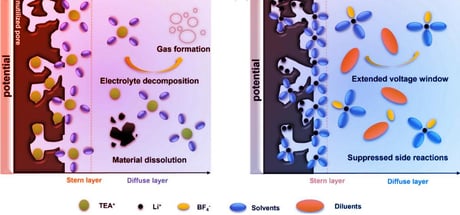
Valami elképesztő született a laborban: szuperkondenzátor, amelyben a legújabb trükk a lignin-alapú, szuperporózus szén elektróda, amit egy teljesen új, fluorozott oldószeres elektrolittal turbóztak fel...
Képzeld el, hogy miközben épp a koktélodat kortyolod, vagy a Netflixen lazulsz, a gépeden egy MI dolgozik tovább – és ez most már nem csak sci-fi, hanem valóság...
A katari Ras Laffan Ipari Városban található folyékonyföldgáz-üzem, amely korábban a világ egyik legnagyobb LNG-előállító központja volt, teljesen leállította termelését az iráni légicsapások nyomán...
🔬 Évtizedek óta nagy fejtörést okozott a kutatóknak, hogy a vörös óriáscsillagok felszínén miként jelennek meg olyan kémiai változások, amelyek eredetileg mélyen, a csillag belsejében keletkeztek...
Vasárnap éjszaka az Air Canada Montrealból érkező gépe tragikus módon összeütközött egy tűzoltóautóval a New York-i LaGuardia repülőtér kifutópályáján...
Valaki betört a BuddyBoss frissítési rendszerébe, és szó szerint tömegével fertőzött meg WordPress-oldalakat, amelyekre közösségi platformokat, tagsági oldalakat vagy e-learning-felületeket húztak...
🔐 A holland pénzügyminisztériumot múlt héten kibertámadás érte, amelynek során illetéktelenek hozzáfértek a minisztérium néhány fontos informatikai rendszeréhez...
💻 Megemlíthető, hogy az Apple idén június 8–12. között rendezi meg éves Worldwide Developers Conference (WWDC) rendezvényét, amely immár online formában hozza össze a világ fejlesztőit egy hétre...
🔒 Egy frissen kiszivárgott szoftvercsomag most minden régebbi iPhone-t veszélybe sodor. A DarkSword nevű, iPhone-okat célzó exploit egyetlen letöltéssel beszerezhető a GitHubon, használatához pedig semmiféle különleges tudás nem kell – néhány kattintással a támadók teljes hozzáférést szerezhetnek a személyes adataidhoz...
Az inzulintabletta ötlete több mint száz éve foglalkoztatja a tudósokat, de eddig mindig kudarcba fulladt: a bélrendszer lebontotta az inzulint, mielőtt eljutott volna a vérbe, így millióknak maradt a napi injekció...
🕹 A mobilos játékosok világa hamarosan izgalmas újdonsággal bővülhet, mivel egy nagy gyártó, minden jel szerint a OnePlus, saját Android-alapú kézikonzol fejlesztésén dolgozik...