Az Alibaba Cloud új, Aegaeon nevű GPU-pool rendszere forradalmasította a vállalat MI-infrastruktúráját: a rendszernek köszönhetően mindössze 213 darab Nvidia H20 gyorsítóval képesek lettek ugyanannyi munkát elvégezni, amelyhez korábban 1192 GPU-ra volt szükség. Az áttörés részleteit a 2025-ös ACM Operációs Rendszerek Szemináriuma (ACM Symposium on Operating Systems, SOSP) konferencián mutatták be Szöulban.
Megosztott erőforrások, maximális hatékonyság
Az Aegaeon előnye, hogy nem egyetlen modellt köt le egyetlen GPU-ra, hanem virtualizálja a GPU-hozzáférést egészen a token szintjéig. Így több MI-modell futtatható egyszerre egyetlen chipen, mindig az éppen szükséges erőforrás-lefoglalással. A rendszer hatékonysága kilencszeresére nőtt a hagyományos szerver nélküli megoldásokhoz képest.
Több hónapos, éles tesztelés
A fejlesztést több hónapon keresztül próbálták ki, több tucat különféle nagy nyelvi modell (LLM), köztük akár 72 milliárd paraméterrel rendelkező változatok futtatására. A részletekről a Pekingi Egyetem és az Alibaba mérnökei publikáltak, kiemelve, hogy ős Nvidiás H20-asokat alkalmaztak – azért, mert a jelenlegi amerikai exportkorlátozások miatt ezek a típusok még elérhetők Kínában.
2025, adrienne, hardware.slashdot.org alapján
Legfrissebb posztok
MA 07:11
Fizetős iOS appok és játékok, amik ingyenesek a mai napon. Mutazione (iPhone/iPad)A Mutazione egy kalandjáték, amelyben egy kisvárosban élő mutánsok mindennapjaiba nyerhetsz betekintést...
MA 06:05
Viharos nap a történelemben: a Holland Kelet-indiai Társaság megszületésétől 🧭 a napóleoni Száz Nap kezdetéig, Einstein relativitáselméletétől 🧠 a modern háborúk fordulópontjaiig...
csütörtök 07:12
Fizetős iOS appok és játékok, amik ingyenesek a mai napon. Mutazione (iPhone/iPad)A Mutazione egy kalandjáték, amelyben a vidéki kisváros hétköznapi pletykái és a természetfeletti események keverednek...
csütörtök 06:06
Mi történt ma a történelemben? A Mongol Birodalom győzelmével véget ér a Szung-dinasztia Kínában 🇨🇳, az angol alsóház eltörli a Lordok Házát 🏛️, a náci csapatok megszállják Magyarországot 🇭🇺, és a Tuskegee Airmen egységet hivatalosan aktiválják ✈️...
szerda 12:01
📦 Az IKEA új, mindenki számára elérhető okos kütyüi végre megérkeztek! A gondolat izgalmas: menő, okos izzók, kapcsolók, dugaljak, mind kezdőáron, már 2400 forinttól...
szerda 11:34
🛡 Egy új, böngészőkben alkalmazható trükk lehetővé teszi, hogy rosszindulatú parancsokat rejtsenek el közvetlenül a weboldalakon anélkül, hogy azt az MI‑asszisztensek észrevennék...
szerda 11:23
😍 Fontos kérdés, hogy mennyire lehet egy okostelefont olcsón, akár otthon is fejleszteni, főleg, ha új funkciók utólag is elérhetők lesznek...
szerda 11:13
💉 Az Egyesült Államokban egyre fiatalabbakat érint a vastagbélrák, amely immár a leggyakoribb daganatos halálok az 50 év alattiak körében...
szerda 11:01
A Google újraírta a szabályokat: mostantól a Geminiben mindenki számára ingyenesen elérhető az a funkció, amellyel valóban személyre szabott válaszokat adhat...
szerda 10:50
Jellemző példa erre, hogy napjaink egyik legagresszívebb ellátásilánc-támadása, a GlassWorm ismét lecsapott: több mint 400 fejlesztői csomag, forráskódtár és bővítmény vált fertőzötté olyan platformokon, mint a GitHub, az npm, a Visual Studio Code és az OpenVSX...
szerda 10:43
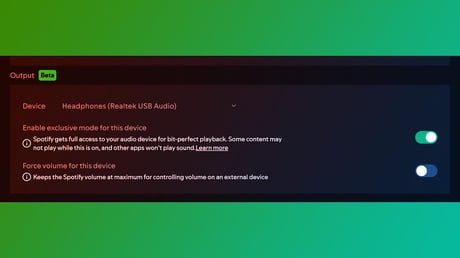
🎧 A Spotify most végre bevezette az Exkluzív módot (Exclusive Mode) Windowsra – innentől a szoftver ráteszi a kezét a hangkártyádra, és kiküszöböli, hogy a géped belemotyogjon a zenédbe...
szerda 10:36
🔒 Az Apple először élesítette a Háttérbiztonsági fejlesztések nevű rendszerét, amellyel anélkül javíthattak egy kritikus WebKit-sebezhetőséget, hogy a teljes operációs rendszert frissíteni kellett volna...
szerda 10:30
Modern munkahelyeken sokan hiszik, hogy a legjobb ötletek maguktól érvényesülnek: az győz, aki meggyőzően érvel, vagy eredeti meglátással áll elő...
szerda 10:23
💰 Március 1-jén nagyszabású kibertámadás érte a nagy nemzetközi kriptopénzes fizetési és ajándékkártya-platformot, a Bitrefillt...
szerda 10:16
😱 A korai gyermekkori stressz nem csupán mentális sebeket hagyhat maga után, hanem a bélrendszer működését is átrendezheti...
szerda 10:10
Miközben az iráni háború felbolygatta a globális olajpiacot, az üzemanyagárak soha nem látott magasságokba emelkedtek Amerikában...
szerda 09:57
🔒 Az Apple beindította a háttérben letöltődő biztonsági javításokat, amelyek olyan észrevétlenül érkeznek, hogy talán észre sem veszed őket – de a telefonod vagy a géped nagyon hálás lesz érte...
szerda 09:51
Az elmúlt hetek eseményei szinte megbénították a Hormuzi-szoros forgalmát: ahol korábban naponta több mint 100 tanker haladt át, most viszont február vége óta alig 21 tette meg az utat...
szerda 09:44
📈 A látszólagos tőzsdei robbanás ellenére a befektetők már hónapok óta gyakorlatilag medvepiacban mozognak...
szerda 09:29
Szóval végre valami, aminek most tényleg lehet örülni bérlőként: az albérletpiacon közel 12 éve nem látott szintre emelkedtek az extra kedvezmények...
szerda 09:23
A Meta frissen felvásárolt MI-startupja, a Manus most egy asztali alkalmazással hozza el saját mesterségesintelligencia-ügynökét közvetlenül a felhasználók számítógépeire...
szerda 09:16
🔥 Mielőtt bárki eltemetné az FBC: Firebreak-et, fontos tudni, hogy a Remedy kiadta hozzá az utolsó tartalmi frissítést—de cseppet se aggódj, a szerverek még évekig bírni fogják a strapát...
szerda 09:11
👑 A francia Mistral AI bemutatta a Forge nevű platformját, amellyel cégek és állami intézmények saját MI-modelleket építhetnek, továbbfejleszthetnek és folyamatosan igazíthatnak a saját adataikhoz szabva – mindezt teljes körű adatvédelem mellett...
szerda 09:01
💸 Fontos kérdés, hogy mi történik az XRP árfolyamával a következő napokban...
szerda 08:57
👑 A Pokémon GO valaha csak játék volt, ma már viszont sokkal több: szinte észrevétlenül a városi robotok navigációs segédeszközévé vált...
szerda 08:38
🔒 Kezdetben az MI-fejlesztések fő fókuszában a képességek és a funkcionalitás állt, de most először jelent meg egy átfogó biztonsági rendszer már a kiadás pillanatában...
szerda 08:30
Az MI-alapú ügynökök egyre több vállalatnál végzik el helyettünk az érzékeny feladatokat: CRM-rendszerekbe lépnek be, adatbázisokat olvasnak, e-maileket küldenek...
szerda 08:23
A ChatGPT szinte mindig magabiztos válaszokat ad, bármiről kérdezed is. Olyan határozottsággal érvel, hogy első ránézésre meggyőző lehet – ugyanakkor könnyen elfeledteti, hogy az általa közvetített válasz csupán egy nézőpont, nem pedig az egyetlen érvényes megoldás...
szerda 08:08
🤔 Érdemes megvizsgálni, mennyire megbízható valójában egy olyan népszerű MI, mint a ChatGPT, ha tudományos állításokról van szó...